We provide depth, RGB and IR images of front car cabin for both real and synthetic imagesets. Corresponding to the images, ground truth annotations for 2D and 3D object detection and instance segmentation are provided. The depth images are provided as uint16 .png files with the values being in millimeters.
Real Imageset
The data has been divided into separate folders according to the camera pose. Within each folder, there are 5 directories named Depth, RGB, IR, RGB videos and Labels containing depth, RGB, infrared images, RGB videos and labels respectively. All images are further grouped into sequence folders such that frames from the same recording are grouped in one folder.
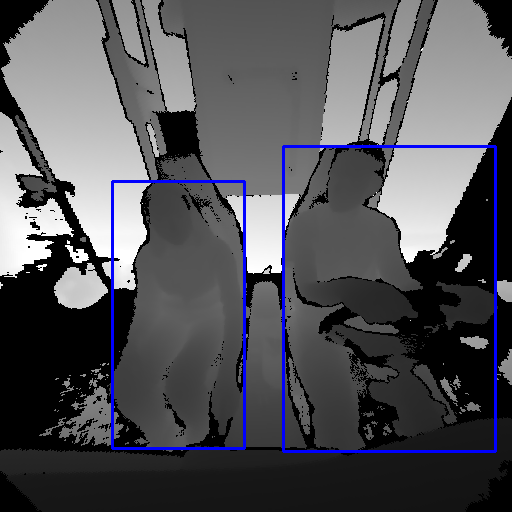 2D Bounding Box
2D Bounding Box 3D Bounding Box
3D Bounding Box Instance Segmentation Mask
Instance Segmentation Mask
Directory Structure
Real_train
├──────Depth
├────────────CS00
├────────────CS01
├────────────CS02
├────────────CS03
├────────────CS04
├────────────CS05
├──────IR
├──────RGB
├──────Labels
├──────RGB_Video
Real_test
├──────Depth
├──────IR
├──────RGB
├────────────CS00
├────────────CS01
├────────────CS02
├────────────CS03
├────────────CS04
├────────────CS05
├──────Labels
├──────RGB_Video
Semantic and instance segmentation
For each image, two masks are provided: class mask and instance mask. Each pixel value in class mask corresponds to the class_id of the class that the pixel belongs to. Whereas each pixel value in the instance mask corresponds to the count of instances for that particular class. For example, if an image contains one person and one book, the instance mask values will be 1 for both the person and the book. However, if an image consists of two persons, the instance mask will contain 1 where the first person appears and 2 where the second person appears in the image. The masks are saved as .png images. Following dictionary maps class_ids used in class masks to their class labels.
class_ids = {
0: 'Background',
1: 'Person'
2: 'Backpack',
3: 'WinterJacket',
4: 'Box',
5: 'WaterBottle',
6: 'MobilePhone',
7: 'Blanket',
8: 'Accessory',
9: 'Book',
10: 'Laptop',
11: 'LaptopBag',
12: 'Infant',
13: 'Handbag',
14: 'FF', #Front-facing childseat
15: 'RF', #Rearfacing childseat
16: 'Child'
}
Bounding boxes
For each sequence, we provide 2 CSV files containing the 2D and 3D bounding boxes for all the images from that sequence.
2D Bounding Boxes
The columns in the CSV files are titled as the following:
frame, label , x_min, y_min, x_max, y_max, low_remission
where the (x_min, y_min) and (x_max,y_max) are the top-left and bottom-right corners of the bounding boxes respectively and low_remission indicates if the object has very few pixels visible in the depth image due to its black color or high reflectivity or both.
As an example, such a file could look as follows:
541,Person,289,179,510,447,0
541,WaterBottle,184,279,211,328,1
3D Bounding Boxes
The columns in the CSV files are titled as the following:
frame, label, cx, cy, cz, dx, dy, dz, phi_x, phi_y, phi_z,low_remission
where cx, cy, cz denotes the center coordinates of the box with respect to the world coordinate system;
dx, dy, dz are the height width and length of the box in meters.
phi_x, phi_y, phi_z are the rotation angles around each axis of the box and are computed in the order of Z-Y-X. They represent the rotation around each axis if the box is located in cx=cy=cz=0
541,Person,0.360624536307132,0.322685483253928,-0.778002920751969,0.487329968638436,0.73777007681433,0.540824891743204,0,0,0,0
541,WaterBottle,-0.390291526217582,0.605084718226563,-0.478073102283553,0.112791408149027,0.29234792119925,0.110232273061841,0,0,0,1
Activity Annotations
For all sequences with people in the driver’s or passenger’s seat, we provide a csv file describing the activities done throughout the sequence with columns structured as follows:
activity_id, activity_name, person_id, 'driver'OR'passenger, start_frame, end_frame, duration
The activity ids and the actions they represent are described in the following dictionary:
activity_ids = {
1: 'drive',
2: 'look_left_while_turning_wheel',
3: 'look_right_while_turning_wheel',
4: 'touch_screen',
5: 'open_glove_compartment',
6: 'touch_head_or_face',
7: 'lean_forward',
8: 'turn_left',
9: 'turn_right',
10: 'turn_backwards_while_reversing',
11: 'adjust_sun_visor',
12: 'turn_backwards',
13: 'talk',
14: 'take_something_from_dashboard',
15: 'sitting_normally',
16: 'read_paper_or_book',
17: 'bending_down',
18: 'using_phone',
19: 'using_laptop'
}
Synthetic Imageset
Images can be downloaded as RGB, grayscale (simulated active infrared camera system) or depth maps. However, sceneries can appear quite dark when RGB images are used. The ground truth data is identical for all three types of images. More information on rendering of this dataset can be found here.
 |  |
| Instance Segmentation Mask | 2D Bounding Boxes |
Directory Structure
Synthetic_Dataset
├──────boundingBoxes2D_wholeImage
├──────boundingBoxes3D_wholeImage
├──────camera_intrinsics
├──────depthmaps_normalized
├──────element_segmentations_wholeImage
├──────exr_wholeImage
├──────pointcloud_objects
├──────RGB_wholeImage
File names
The file names of all the different ground truth data and images are constructed in the following way, such that most of the important information is already included in the naming:
[car_name]_train_imageID_[imageID]_GT_[GT_label_left]_0_[GT_label_right].file_extension
The following dictionary describes the content of GT_label_left and GT_label_right:
GT_labels = {
0: Empty Seat,
1: Infant in an Infant Seat,
2: Child in a Child Seat,
3: Person,
4: Everyday Objects,
5: Empty Infant Seat,
6: Empty Child Seat
}
As the rectangular images contain only information about a single seat, the naming is slightly different. However, the imageID still refers to the whole image and we additionally specify which seat is shown (0 for left and 2 for right) :
[car_name]_train_imageID_[imageID]_seatPosition_[seatPosition]_GT_[GT_label].file_extension
Semantic and instance segmentation
We provide a position and class based instance segmentation mask, which can be used as ground truth data for semantic and instance segmentation. For both tasks, we have five different classes and we want to separate infants/children from their seats and classify them as persons.
Each pixel is colored according to which object it belongs to, but also according to which seat (left or right) the object is placed on.
The masks need to be converted to integer values, because most cost functions and deep learning frameworks ask for an integer value as ground truth label. A simple approach to get a label between 0 and 4 is to transform the mask to grayscale. For example, one can use PIL and the following function:
from PIL import Image
Image.open(path_to_mask).convert('L')
After that, each grayscale value can be converted to an integer (and position) using the following function:
def get_class_by_gray_pixel_value(gray_pixel_value):
"""
Returns for a grayscale pixel value the corresponding ground truth label as an integer (0 to 4).
Further, the function also outputs on which seat the object is placed (left or right).
The relationship between gray_pixel_value and the class integer depends on the grayscale transformation function used.
These functions should work fine with PIL and OpenCV.
0 = background
1 = infant seat
2 = child seat
3 = person
4 = everyday object
Keyword arguments:
gray_pixel_value -- grayscale pixel value between 0 and 225
Return:
class_label, position
"""
# background
if gray_pixel_value == 226 or gray_pixel_value == 225:
return 0, None
# infant
if gray_pixel_value == 173 or gray_pixel_value == 172:
return 1, "left"
# child
if gray_pixel_value == 175 or gray_pixel_value == 174:
return 2, "left"
# person
if gray_pixel_value == 29:
return 3, "left"
if gray_pixel_value == 132 or gray_pixel_value == 131:
return 3, "right"
# everyday objects
if gray_pixel_value == 105:
return 4, "left"
# infant seat
if gray_pixel_value == 76:
return 5, "left"
# child seat
if gray_pixel_value == 150 or gray_pixel_value == 149:
return 6, "left"
return None, None
Notice: depending on which function and library you use to convert the mask to grayscale, different values need to be used in the above function, because different libraries might use different grayscale transformations. The above function should work with PIL and openCV.
Bounding Boxes
For each scenery, we provide a single text file that contains the 2D and 3D bounding boxes of all objects in the scene. We assume that the origin of the images is at the upper left corner.
The class_label is defined according to the following dictionary:
class_label = {
1: Infant,
2: Child,
3: Person,
4: Everyday Object,
5: Infant Seat,
6: Child Seat
}
2D Bounding Boxes
Each line in the text file corresponds to a different object and each line contains the following information:
[class_label], [x_upper_left_corner], [y_upper_left_corner], [x_lower_right_corner], [y_lower_right_corner]
As an example, such a file could look as follows:
4,180,297,200,315
3,256,135,511,409
In this scenery, we would have an everyday object (label 4) on the right seat and a driver (label 3) at the left seat.
3D Bounding Boxes
Similarly, each line in the 3d Bounding Boxes files corresponds to an object and is formatted as follows:
[class_label], [cx], [cy], [cz], [dx], [dy], [dz]
where cx, cy, cz denotes the center coordinates of the box with respect to the world coordinate system and dx, dy, dz are the height width and length of the box in meters.
An example from the dataset looks like this:
4,0.3701785599899538,-0.4916732776363616,1.2793812155723572,0.12447861816428218,0.14179835409594016,0.11465275287628174
3,0.06548566626832714,0.5524043367740695,0.8297426104545593,1.3961034349258976,1.104808673548139,0.5170959234237671
Keypoints
For each scenery, we provide a single .json file which includes the poses of all people (babies included) in the scene. We save the human poses by using keypoints, as used by the COCO dataset, but our skeleton is defined using partially different joints. The .json file contains the 2D pixel coordinates of the keypoints of all people together with the visibility flag, the bone names and their seat position. It is constructed as follows:
{
[name_of_person_1_in_the_scene]: {
"bones": {
[name_of_bone_1]: [
[x_coord],
[y_coord],
[visibility]
],
[name_of_bone_1]: [
[x_coord],
[y_coord],
[visibility]
],
.
.
.
},
"position": [seat_position_of_person_1]
},
[name_of_person_2_in_the_scene]: {
"bones": {
.
.
.
},
"position": [seat_position_of_person_2]
}
.
.
.
}
Here is a list of bone names used in our benchmark:
["head", "clavicle_r", "clavicle_l", "upperarm_r", "upperarm_l", "lowerarm_r", "lowerarm_l", "hand_r", "hand_l", "thigh_r", "thigh_l", "calf_r", "calf_l", "pelvis", "neck_01", "spine_02", "spine_03"]
The visibility of the keypoints are set to
- 0, if the keypoint is outside the image,
- 1, if it is occluded by an object or neighboring human,
- 2, if it is visible or occluded by the person itself.
For the benchmark evaluation, only the bones with a visibility of 2 are considered. Usually, this means that bones with a visibility of 0 and 1 are set to a visibility of 0 and the bones with a visibility of 2 are set to a visibility of 1.
